
Nop平台为什么是一个独一无二的开源软件开发平台
- 2023-10-19 11:20:46
- canonical 原创
- 2376
Nop平台与其他开源软件开发平台相比,其最本质的区别在于Nop平台是 从第一性的数学原理出发,基于严密的数学推导逐步得到各个层面的详细设计。它的各个组成部分具有一种内在的数学意义上的一致性。这直接导致Nop平台的实现相比于其他平台代码要短小精悍得多,而且 在灵活性和可扩展性方面也达到了所有已知的公开技术都无法达到的高度,可以实现系统级的粗粒度软件复用。而主流的技术主要基于组件组装的思想进行设计,其理论基础已经决定了整体软件的复用度存在上限。
Nop平台遵循了可逆计算理论所制定的技术战略
App = Delta x-extends Generator<DSL>为了落实这一技术战略,Nop平台使用了如下具体的战术手段。
一. DSL森林
在Nop平台中,能使用DSL(Domain Specific Language)描述的逻辑一定会使用DSL来描述。这与主流框架的设计思想是完全不同的。比如说,
- Hibernate中引入数据库方言对象需要指定一个Dialect类,而在Nop平台中我们会增加一个dialect.xml模型文件
- Hibernate中定义对象与数据库表之间的映射关系主要使用代码中的JPA注解(最新的Hibernate6.0已经取消hbm支持),而在Nop平台中我们使用orm.xml模型文件
- SpringBoot通过注解来实现复杂条件装配,而在Nop平台中为Spring1.0语法的beans.xml增加了条件判断扩展,可以在beans.xml模型文件中实现类似SpringBoot的条件装配功能。
- 解析Excel模型文件一般要么像EasyExcel那样只支持简单结构,要么靠程序员手工编写针对某个固定格式的解析代码,而Nop平台中我们可以通过imp模型来描述存储在Excel文件中的复杂领域对象结构,自动实现解析,并自动实现Excel生成。
图灵奖得主Michael Stonebraker在批判MapReduce技术时曾指出,数据库领域这四十年来中学到了三条重要的经验:
- Schemas are good.
- Separation of the schema from the application is good.
- High-level access languages are good.
如果我们想要将上述三条经验推广到更广泛的编程领域,那么我们必然需要创建自定义的高层语言,也就是所谓的DSL。DSL提高了信息表达密度,同时也提升了业务逻辑的可分析性和可迁移性。我们可以分析描述式的DSL结构反向提取出大量信息,并且将它迁移到新的模型中。例如百度的AMIS框架在宣传时总是强调AMIS的页面描述长期保持稳定,而底层的实现框架已经升级换代了很多次。我们甚至可以编写一个转换器,将AMIS的描述转换到某种我们自己编写的Vue组件框架上。
在可逆计算理论的概念框架下,我们需要强调信息表达的可逆性,即通过某种形式表达的信息应该可以被逆向抽取,转换为其他形式。而不是像今天的软件一样,信息被固化在具体的语言、框架中,升级底层框架是一件成本高昂的奢侈行为。
传统上Schema只是用于约束某种数据对象,但当我们系统化的使用DSL来解决问题时,我们所面对的不再是单一的某一个DSL,而是众多DSL所组成的DSL森林,在这种情况下,我们有必要为DSL引入独立的Schema定义,也就是所谓的元模型:描述模型的模型。
二. 统一的元元模型
主流框架的设计可以说是各自为战,比如工作流引擎、报表引擎、规则引擎、GraphQL引擎、IoC引擎、ORM引擎等等,各自编写自己的模型解析和序列化代码,各自独自编写自己的格式校验。如果需要可视化设计工具,则每个框架都自己独自编写一套。一般情况下,除非出自大公司或者成为某个商业产品的一部分,我们很难看到一个框架具有对应的IDE插件,具有良好可用的可视化设计工具。
如果所有的模型底层具有严格定义的内在一致性,我们就可以 通过逻辑推导自动实现大量功能而无需针对每一种模型单独编写。而统一的元元模型是实现内在一致性的关键手段。
- 模型(元数据)是描述数据的数据
- 元模型是描述模型的模型(数据)
- 元元模型是描述元模型的模型(数据)
举例来说,
- ORM模型文件app.orm.xml定义了一个数据库存储模型
- ORM模型的结构由它的元模型orm.xdef来描述
- 在Nop平台中,所有的模型都采用统一的XDef元模型语言来描述,而XDef元模型语言的定义xdef.xdef就是所谓的元元模型。有趣的是,XDef由XDef自己来定义,所以我们不再需要元元元模型。
Nop平台根据XDef元模型自动得到模型解析器、验证器等,通过统一的IDE插件实现代码提示、链接跳转以及断点单步调试等功能。更进一步,Nop平台可以根据XDef元模型描述以及扩展的Meta描述, 自动为模型文件生成可视化设计器。借助于公共的元模型以及内嵌的Xpl模板语言,我们可以 实现多个DSL之间的无缝嵌入。比如在工作流引擎中嵌入规则引擎,在报表引擎中嵌入ETL引擎等。此外, 统一元元模型使得复用元模型成为可能,比如designer模型和view模型都引用了公共的form模型。复用元模型可以极大的提升系统内部语义的一致性,从根源上减少概念冲突,提升系统的复用性。
Nop平台所提供的是所谓的领域语言工作台(DSL Workbench)的能力。我们可以利用Nop平台来快速的开发新的DSL或者扩展已有的DSL,然后再使用DSL来开发具体的业务逻辑。
Nop平台作为一个低代码平台,它自身的开发也是采用的低代码的开发方式。一个显著的结果是,Nop平台中手工编写的代码量相比于传统框架的代码量大为下降。 以Hibernate为例,它具有至少30万行以上的代码量,却长期存在着不支持在From子句中使用子查询,不支持关联属性之外的表连接、难以优化延迟属性加载等问题。NopORM引擎实现了Hibernate+MyBatis的所有核心功能,可以使用大多数SQL关联语法,支持With子句、Limit子句等,同时增加了逻辑删除、多租户、分库分表、字段加解密、字段修改历史跟踪等应用层常用的功能,支持异步调用模式,支持类似GraphQL的批量加载优化,支持根据Excel模型直接生成GraphQL服务等。 实现所有这些功能,NopORM中手写的有效代码量只有1万行左右。类似的,在Nop平台中我们通过4000行左右的代码实现了支持条件装配的NopIoC容器,通过3000行左右的代码实现了支持灰度发布的分布式RPC框架,通过3000代码实现了采用Excel作为设计器的中国式报表引擎NopReport等。具体介绍参见以下文章:
三. 差量化
在软件开发中,所谓的可扩展性指的是在不需要修改原始代码的情况下,通过添加额外的代码或差异信息,可以满足新的需求或实现新的功能。如果在完全抽象的数学层面去理解软件开发中的扩展机制,我们可以认为它对应于如下公式:
Y = X + Delta- X对应于我们已经编写完毕的基础代码,它不会随需求的变化而变化
- Delta对应于额外增加的配置信息或者差异化代码
在这个视角下,所谓的可扩展性方面的研究就等价于Delta差量的定义和运算关系方面的研究。
主流的软件开发实践中所使用的扩展机制存在如下问题:
- 需要事先预测在哪些地方可能会进行扩展,然后在基础代码中定义好扩展接口和扩展方式
- 每一个组件能够提供哪些扩展方式和扩展能力都需要单独去设计,每个组件都不一样
- 扩展机制往往会影响性能,扩展点越多,系统性能越差
以SpringBoot为例,如果我们在基础代码中创建了两个bean:beanA和beanB,在扩展代码中我们希望删除beanA,扩展beanB,则需要修改基础代码,在配置类的工厂方法上增加SpringBoot特有的注解。除了直接使用注解之外,SpringBoot也提供了其他机制可以对bean的创建过程进行精细控制,但是这些做法都需要实现Spring框架内部的接口,并且了解IoC容器的执行细节。如果我们弃用Spring容器,换成Quarkus等其他IoC框架,则针对Spring容器所设计的扩展机制就失去了意义。
@Configuration class MyConfig{ @Bean @ConditionalOnProperty(name="beanA.enabled",matchIfMissing=true) public BeanA beanA(){ return new BeanA(); } @Bean @ConditionalOnMissingBean public BeanB beanB(){ return new BeanB(); } }Nop平台基于可逆计算原理,建立了一整套系统化的差量分解、合并的机制,可以使用非常统一、通用的方式来实现差量化扩展。特别的,所有的DSL模型文件都支持Delta定制机制,可以在_delta目录下增加同名的文件来覆盖基础代码中已有的文件。以上面的Bean定制逻辑为例,
<!-- /_delta/default/beans/my.beans.xml 将会覆盖 /beans/my.beans.xml文件 -->
<beans x:extends="super" x:schema="/nop/schema/beans.xdef">
<!-- 删除基础代码中定义的beanA -->
<bean id="beanA" x:override="remove" />
<!-- 在已有的beanB的配置基础上,增加fldA的设置 -->
<bean id="beanB" >
<property name="fldA" value="123" />
</bean>
</beans>这种DSL层面发生的Delta合并过程适用于Nop平台中的所有底层引擎,例如ORM引擎、工作流引擎、规则引擎、页面引擎等都可以使用类似的方式进行扩展定制。 运行时引擎完全不需要内置任何关于此类可扩展性的知识。例如,在NopIoC引擎中,我们没有像SpringBoot那样设计大量的扩展接口,也没有在运行时执行大量的判断逻辑,而是尽量在DSL模型的编译阶段以统一的方式来实现动态扩展。
基于Nop平台开发的软件产品无需在应用层做出特殊设计即可实现系统级的软件复用,在定制开发的时候可以复用整个基础产品。例如基于Nop平台开发的银行核心系统,在不同的银行进行定制化部署实施的时候,不需要修改基础产品的源码,只需要增加Delta差量代码即可。通过这种方式,我们可以实现 基础产品和定制化版本之间的并行演化。
具体技术方案可以参见以下文章:
可逆差量的概念相对比较新颖、抽象,导致一些程序员理解起来存在很多误解,为此我专门写了如下概念辨析的文章:
四. 模板化
目前主流的软件开发实践本质上仍然是手工作业模式,大量的程序逻辑都是通过程序员手工编写完成。如果要实现软件的自动化生产,那么我们必须要使用智能化的代码生成机制来替代手工编写。
Nop平台基于可逆计算原理将差量化编程和产生式编程(Generative Programming)有机的结合在一起,支持自动生成的代码与手工修正的代码协同工作,通过元编程和代码生成工具渐进式的引入代码生成能力,极大拓宽了产生式编程范式的应用范围。而传统的代码生成方案,一旦自动生成的代码不满足需求需要手工修改,则被修改的代码就脱离了自动化生产流程,被迫成为手工维护的技术资产的一部分,在长期的系统演化过程中,大量自动生成的、结构不直观却必须要手工维护的代码很有可能发展成为技术负债,成为负资产。
代码生成原则上可以使用各种各样的实现方案,只要最终的输出产物满足需求规格要求即可。但是如果希望代码生成的过程尽量维持直观性,而且可以实现代码生成与DSL自身的结构表达无缝接驳在一起,我们需要使用模板化的代码生成方案。所谓的模板(Template)就是以目标结构为基础进行模板化加工,在其上增加一些额外的标注,或者将某些部分替换为${xxx}这种形式的动态表达式。
Nop平台非常强调模板本身与目标结构之间的同态性和同像性(homoiconicity)。
同态性
同态性指的是模板自身与输出目标具有相似的结构,最理想的情况下模板本身甚至就是一个合法的目标结构。这方面最直观的例子是Nop平台中的Excel报表和Word报表的设计。它们本质上都是以底层OfficeXML为基础,在其上通过注解等内置的扩展机制补充表达式信息,从而将原始的领域对象转换为模板化对象。 如果抹去模板对象上的一些扩展属性,我们实际上可以得到一个合法的Office文件,并且可以使用Office软件来编辑它! 反过来考虑,在实现可视化设计器的时候,如果内置了与模板化相互配合的扩展机制,则我们可以将普通的领域对象设计器增强为模板设计器。
具体方案参见以下文章:
为了保持模板与输出目标之间的结构相似性,在Nop平台中我们还系统化的使用了前缀引导语法,在自动化测试的模板匹配语法以及测试数据生成器中都得到了应用。具体参见
当模板自身具有很强的结构化特征时,我们就可以使用XDSL通用的Delta定制机制来实现对模板本身的定制。
同像性
同像性是源自于Lisp函数式语言的一种特性,它指的是模板语言的语法结构和抽象语法树同形,因此可以用模板语言直接生成可执行的模板代码。Nop平台的做法是采用XML语法作为基础结构语法,模板语言采用XML格式,它的输出结果也是合法的XML。例如
<orm> <c:for var="entity" items="${ormMode.entities}"> <orm-gen:GenEntity entity="${entity}" /> </c:for> </orm>保持同像性有如下好处:
- 便于引入自定义的程序语法,在使用层面自定义语法和语言内置语法完全等价
- 在元编程阶段可以通过统一的XNode结构来描述DSL语法,对程序结构进行变换和操作普通的Tree数据一样简单
- 便于跟踪生成代码所对应的模板源码位置。模板语言本身相当于是采用了AST语法树形式,它的输出结果不是简单的文本内容,而是新的AST节点(XNode)。如果只是文本内容,则没有办法进一步继续进行结构化处理,也没有很简单的方法跟踪生成的代码所对应的模板源码位置。
五. 多阶段分解
Nop平台大量采用代码生成机制通过自动推理来生产代码,但是如果推理链条比较长,使用一步到位的代码生成方案会导致模型定义过于复杂,而且使得不同抽象层面的信息无序混杂在一起。对于这种情况,Nop平台提供了一条标准的技术路线:
- 借助于嵌入式元编程和代码生成,
任意结构A和C之间都可以建立一条推理管线
-
将推理管线分解为多个步骤 : A => B => C
-
进一步将推理管线差量化:A =>
_B=> B =>_C=> C
-
每一个环节都允许暂存和透传本步骤不需要使用的扩展信息
例如在Nop平台中我们内置了一条从Excel数据模型自动生成前后端全套代码的推理i管线。
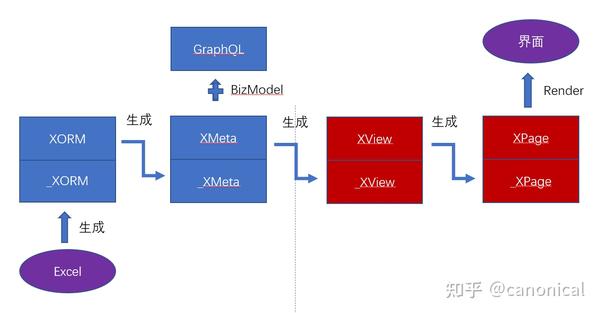
具体来说,从后端到前端的逻辑推理链条可以分解为四个主要模型:
- XORM:面向存储层的领域模型
- XMeta:面向GraphQL接口层的领域模型
- XView:在业务层面理解的前端逻辑,采用表单、表格、按钮等少量UI元素,与前端框架无关
- XPage:具体使用某种前端框架的页面模型
根据Excel模型可以自动生成_XORM模型,然后在此基础上我们可以补充差量配置信息形成最终使用的XORM模型。下一步,我们再根据XORM模型生成_XMeta模型,依此类推。如果写成数学公式,相当于是
XORM = CodeGen<Excel> + DeltaORM
XMeta = CodeGen<XORM> + DeltaMeta
XView = CodeGen<XMeta> + DeltaView
XPage = CodeGen<XView> + DeltaPage整个推理关系的各个步骤都是可选环节: 我们可以从任意步骤直接开始,也可以完全舍弃此前步骤所推理得到的所有信息。
比如,我们可以手动增加XView模型,并不需要它一定具有特定的XMeta支持,也可以直接新建page.yaml文件,按照AMIS组件规范编写JSON代码,AMIS框架的能力完全不会受到推理管线的限制。
基于可逆计算理论设计的低代码平台NopPlatform已开源:
| 联系人: | 北柠 |
|---|---|
| 电话: | 17554229565 |
| Email: | beining@chandao.com |
